
はいデータエンジニアは、企業のデータ活用を支える重要な職種です。ビッグデータの時代において、データの収集・処理・保存・分析の基盤を整える役割を担い、データサイエンティストやアナリストが活用しやすい環境を構築します。本記事では、データエンジニアの仕事内容、求められるスキル、キャリアパスについて詳しく解説します。
データエンジニアの概要
データエンジニアは、企業のデータ管理と活用を支える重要な役割を担う技術者です。データの収集・変換・保存を適切に行い、データサイエンティストやアナリストが活用しやすい形に整えるのが主な業務です。特に近年、ビッグデータやクラウド技術の発展により、データエンジニアの需要は急速に高まっています。
本セクションでは、データエンジニアの役割や仕事内容、他職種との違いについて詳しく解説します。
データエンジニアとは?
データエンジニアは、企業のデータ活用を支える技術者であり、データの収集・処理・保存・管理を担当します。データの正確性や一貫性を保ち、データサイエンティストやアナリストが活用しやすい環境を整備する役割を担います。ビッグデータやクラウド技術の発展により、データエンジニアの重要性はますます高まっています。
| キャリアパス | データエンジニアになる過程 |
|---|---|
| ソフトウェアエンジニア | データ処理の最適化やETLの設計に関わることでデータエンジニアへ移行 |
| データサイエンティスト | データの整理やクレンジングの重要性に気づき、データパイプラインの構築に携わる |
| インフラエンジニア | クラウド環境の設計・運用を通じてデータ基盤の最適化を担当し、データエンジニアへ |
実際に私が機械学習の元となるデータの整理(データクレンジング)業務に従事していた時に思ったことですが、データエンジニアは他の職種(データサイエンティストやデータアナリスト、データベースエンジニア)とは少し性質が違う気がしました。理由は下記の3つです。
- 「専門職」ではなく「データ基盤を支える技術者」
- 「分析や機械学習をする人」ではなく「データを適切に使える状態にする人」
- 「データに関するエンジニアリング全般を担う、ジェネラリスト的ポジション」
データエンジニアの特異性
誤解を恐れずに言うならば「値を導く計算式」ではなく学生時代に勉強した数学で言うところの「証明」に近いと言えば良いのか・・余計誤解を生みそうですが・・ようは目指してなれる職業ではない気がします。
データエンジニアの仕事って、「結果(数値)」を出す人ではなく、結果を導き出すための「論理(証明)」を組み立てる人」 という立ち位置なんですよね。
- データサイエンティストやアナリストが「計算式」を使って結論(価値)を導き出すのに対し、データエンジニアは「証明」のように、その計算が正しく行われるための基盤を作る。
- データの整合性や一貫性、再現性を担保するのがデータエンジニアの役割
- 間違ったデータやバイアスのかかったデータが流れないように、データの出処を明確にし、ロジックを整える
つまり、データエンジニアは、「データを解釈する職種(データサイエンティスト・アナリスト)」が機能するための"数学的証明のような役割"を果たしているというイメージですね。
これを一言で言い表すなら…
- 「データの正しさを証明する人」
- 「データ分析の土台を作る技術者」
- 「データの整合性を担保する職人」
データエンジニアの特異性
- 直接目指す職種ではなく、キャリアの中で形成されることが多い
データサイエンティストやソフトウェアエンジニア、インフラエンジニアなど、何らかの関連職種を経験した後にデータエンジニアへシフトするケースが多い。新卒や未経験から「データエンジニアを目指す」というより、データに関わる仕事をしているうちに必要なスキルが求められ、結果としてデータエンジニアになっている人が多い。 - エキスパートというより"データ基盤のジェネラリスト"的な側面が強い
データエンジニアは、特定の分野に深く特化するよりも、データ基盤全体を広く見渡し、スムーズなデータフローを設計・管理する役割 を担う。そのため、データ処理、データベース設計、クラウド技術、ETLツールの活用、インフラ管理など、さまざまな技術の知識が求められる。逆に、データサイエンティストは機械学習や統計モデルの専門家、データアナリストはビジネス視点での分析の専門家としてのポジションが明確。 - ビジネスインパクトが直接見えにくい
データサイエンティストは、分析や予測モデルを構築して、売上向上や業務効率化などの成果を直接出せる職種。
一方で、データエンジニアは「データが正しく蓄積され、適切に利用できる環境を作る」ことが目的であり、成果が直接数値化されにくい。つまり、「誰かが使うための環境を整える仕事」であり、直接的なアウトプットよりも裏方的なポジション になりやすい。
データエンジニアは「目指す職種」ではなく「キャリアの中で求められる職種」
データエンジニアは、プログラミングやデータベース設計、クラウド技術を学んだからといってすぐになれる職種ではありません。
むしろ、他の職種(ソフトウェアエンジニア、データサイエンティスト、インフラエンジニア、データアナリストなど)として経験を積む中で、データ処理の効率化や基盤の整備が必要になり、その結果としてデータエンジニアにシフトしていくケースが多い です。
そのため、未経験からいきなりデータエンジニアを目指すというよりは、まずはデータを扱う関連職種に就き、実務を通じてスキルを高めながらデータエンジニアの領域に入っていく というキャリアパスの方が自然です。
データエンジニアはどのように生まれるのか?
多くのデータエンジニアは、最初からこの職種を目指していたわけではなく、別の職種での経験を積むうちに、データ処理や管理の重要性に直面し、そこからスキルを広げていくことでデータエンジニアへとシフトしていく ケースが考えられます。
- ソフトウェアエンジニア → データエンジニア
システム開発の中でデータ処理が課題となり、効率的なデータ管理やETLの設計に関わるようになる
データパイプラインやクラウドベースのデータ処理に詳しくなり、データエンジニアとしての役割を担う - データサイエンティスト → データエンジニア
モデル開発のためにデータを整備する過程で、データ基盤の課題に直面する
より良いデータ環境を整えるために、データパイプラインの構築やデータベースの最適化に取り組む - インフラエンジニア → データエンジニア
クラウド環境の設計・運用を行う中で、大規模なデータ処理を最適化する仕事に関わる
データの流れを管理するスキルが求められ、データ基盤の設計にシフトしていく
このように、データエンジニアは、業務の中で「データ処理の課題」に向き合ううちに、その役割を担うようになる職種 です。
結論を言ってしまうと、いきなりデータエンジニアを目指しても、何をしたら良いか分からず路頭に迷うと思います。
未経験からいきなりデータエンジニアを目指すのは難しい?
未経験からデータエンジニアを目指すことは不可能ではありませんが、一般的には、いきなりデータエンジニアの仕事に就くのは難しく、まずはデータを扱う職種の経験を積むことが現実的です。
- SQLやPythonを学び、データ分析の基礎を身につける
- データベースやETL処理に関わる仕事を経験する
- クラウド環境でのデータ処理やデータパイプライン構築を学ぶ
データエンジニアに向いている人とは?
データエンジニアは、専門職というよりも、データを効率的に活用するための「基盤」を作るジェネラリスト的な役割を持ちます。そのため、次のような特徴を持つ人に向いている職種と言えます。
- データ基盤やシステム全体の設計に興味がある人
- データ処理を最適化し、効率的に管理することが好きな人
- 特定の分析や開発よりも、幅広い技術を活用して環境を整えることにやりがいを感じる人
データエンジニアは、目指す職種というより、キャリアの中で求められた結果としてなる職種です。データ活用の課題に直面し、それを解決するためのスキルを身につけるうちに、自然とデータエンジニアの道を歩むことが多いでしょう。
そのため、未経験からいきなりデータエンジニアを目指すのではなく、データに関わる職種を経験しながら、必要なスキルを磨いていくことが最も現実的なアプローチとなります。
データエンジニアの役割と重要性
データエンジニアは、企業がデータを効果的に活用するための基盤を整える専門家です。データの流れを構築・管理し、適切なデータストレージと処理環境を提供することで、企業の意思決定や分析作業を支援します。
データエンジニアの主な業務
| 業務カテゴリ | 具体的な内容 | 主なツール・技術 |
|---|---|---|
| データ収集・ETL | 複数のデータソース(API、データベース、ログ)からデータを取得し、加工・統合 | Python, SQL, Apache Nifi, Talend |
| データパイプラインの設計 | データの流れを自動化し、ストリーミングまたはバッチ処理を実装 | Apache Airflow, Kafka, Kubernetes |
| データベースの設計・管理 | RDBMSやNoSQLを活用し、最適なデータ保存戦略を設計 | MySQL, PostgreSQL, MongoDB, DynamoDB |
| 分析基盤の整備 | ビッグデータ処理環境を構築し、データサイエンティストの分析を支援 | Hadoop, Spark, BigQuery, Redshift |
なぜデータエンジニアが必要なのか?
企業がデータを活用するためには、データの整備・管理・最適化が不可欠です。データエンジニアがいなければ、データは散在し、正確な分析が難しくなります。以下のポイントから、データエンジニアの必要性を説明します。
① データの品質向上
データサイエンティストやアナリストが分析を行うためには、データの品質が重要です。誤ったデータや欠損値が含まれると、誤った分析結果を招くリスクがあります。データエンジニアは、データのクレンジング(欠損値の補完、重複データの削除など)を行い、分析に適したデータセットを提供します。
② データの統合と最適な保存
企業には複数のデータソース(社内システム、外部API、ログデータなど)が存在し、これらを統合することが求められます。データエンジニアは、適切なデータベースやデータウェアハウスを選定し、効率的にデータを保存・管理します。
③ データパイプラインの自動化
手動でデータを収集・処理するのは非効率的であり、人為的ミスの原因になります。データエンジニアは、ETL(Extract, Transform, Load)やデータパイプラインを自動化し、リアルタイムまたは定期的にデータが更新される仕組みを構築します。
④ 分析基盤のスケーラビリティ
データ量が増加すると、処理に時間がかかり、分析の遅延が発生する可能性があります。データエンジニアは、クラウドや分散処理技術を活用し、スケーラブルな分析基盤を整備することで、大量データでも迅速な処理を可能にします。
データエンジニアは、企業のデータ管理と活用の要となる職種です。データの収集・処理・管理を適切に行い、データサイエンティストやアナリストが価値のある情報を抽出できる環境を整えます。データエンジニアの役割がなければ、企業のデータ戦略は成り立たず、ビジネスの成長にも影響を与える可能性があります。
データエンジニアの仕事内容
データエンジニアは、データの収集から処理、保存、最適化、そして分析基盤の構築まで、多岐にわたる業務を担当します。これらの業務を適切に設計・管理することで、データがスムーズに流れ、データサイエンティストやアナリストが活用できる環境を整備します。
データの収集・ETL処理
データエンジニアの業務の中でも、データの収集とETL(Extract, Transform, Load)処理は特に重要なプロセスです。企業が持つデータは、データベース、API、ログファイル、IoTデバイスなど、さまざまなソースから取得されます。これらのデータを適切に取得し、統一フォーマットへ変換し、分析しやすい形で保存することが求められます。
データの取得と前処理
企業が持つデータは、さまざまなソースから取得されます。データの種類や形式が異なるため、適切な取得方法と前処理が重要になります。
| データ取得方法 | 説明 |
|---|---|
| データベース(RDBMS, NoSQL) | SQLクエリを用いたデータ抽出(MySQL, PostgreSQL, MongoDBなど) |
| API連携 | REST APIやGraphQLを利用し、外部システムとデータを統合 |
| ログ・センサーデータの収集 | Webサーバーログ、IoTデバイスのデータ収集(Fluentd, Logstash) |
ETL(Extract, Transform, Load)プロセスの構築
ETLとは、データを抽出(Extract)、変換(Transform)、ロード(Load)する一連のプロセスです。
| フェーズ | 主な作業 | 使用ツール |
|---|---|---|
| Extract(抽出) | データソース(DB、API、ログ)からデータを取得 | Python, SQL, Apache NiFi |
| Transform(変換) | データのクリーニング・統合・集計 | Apache Spark, dbt, Pandas |
| Load(格納) | データウェアハウスやデータレイクに保存 | Amazon Redshift, BigQuery, Snowflake |
データパイプラインの設計と管理
データパイプラインは、データの収集、処理、保存、配信を自動化する仕組みであり、データエンジニアにとって不可欠な技術の一つです。適切に設計されたデータパイプラインは、リアルタイム処理やバッチ処理を最適化し、スムーズなデータフローを実現します。
近年、クラウド環境の発展により、大規模データの処理やスケーラビリティを考慮したデータパイプラインの構築が求められています。
ストリーミング処理とバッチ処理の違い
| 処理タイプ | 特徴 | 主なユースケース |
|---|---|---|
| ストリーミング処理 | リアルタイムでデータを処理 | IoTデバイスのデータ解析、リアルタイムレコメンド |
| バッチ処理 | 一定の時間ごとにデータを処理 | 日次売上レポート、定期的なデータ統合 |
パイプラインの自動化とモニタリング
データパイプラインは、一度構築すれば終わりではなく、自動化と継続的な監視が必須です。
データベースの設計・最適化
データベースの設計と最適化は、データエンジニアの重要な業務の一つです。適切に設計されたデータベースは、データの格納や検索を効率化し、システムのパフォーマンス向上に貢献します。一方で、設計が不十分だと、データの整合性が損なわれたり、クエリの処理速度が低下したりする可能性があります。
RDBMSとNoSQLの選択基準
| データベースの種類 | 特徴 | ユースケース |
|---|---|---|
| RDBMS(リレーショナル) | ACID特性を持つ、スキーマが固定 | トランザクション処理(ECサイト、銀行システム) |
| NoSQL | スキーマレス、スケールしやすい | リアルタイム分析、分散データ処理 |
データモデリングのベストプラクティス
- 正規化 vs 非正規化
- インデックス設計
分析基盤の構築
企業がデータを活用するためには、効率的でスケーラブルな分析基盤の構築が不可欠です。分析基盤とは、データの収集・処理・保存・可視化を一元管理し、データアナリストやデータサイエンティストが容易にアクセスできる環境を指します。適切な分析基盤が整っていれば、ビジネスの意思決定を迅速かつ正確に行うことが可能になります。
データウェアハウスの役割
データウェアハウス(DWH)は、分析目的でデータを格納するシステムです。
| データウェアハウス | 特徴 |
|---|---|
| Google BigQuery | クエリの高速処理が可能 |
| Amazon Redshift | AWSのDWHサービス |
| Snowflake | クラウドネイティブなデータウェアハウス |
ビッグデータ処理技術(Hadoop, Spark, BigQueryなど)
| 技術 | 特徴 | 主な用途 |
|---|---|---|
| Hadoop | 分散ストレージ(HDFS)を活用 | 大規模データの蓄積・処理 |
| Spark | インメモリ処理で高速 | リアルタイム分析 |
| BigQuery | GoogleのフルマネージドDWH | 大規模SQLクエリ |
データエンジニアは、データの収集・処理から分析基盤の構築までを担います。データパイプラインやETLを最適化し、データを活用しやすくする役割を果たします。
データエンジニアと他職種との違い
データエンジニアは、データの収集・処理・保存を担い、データ活用の基盤を整備する役割を持ちます。一方で、データサイエンティスト、データアナリスト、データベースエンジニアといった職種もデータを扱いますが、それぞれの業務内容やスキルセットは異なります。本セクションでは、データエンジニアと他職種の違いを詳しく解説します。
データサイエンティストとの違い
データエンジニアとデータサイエンティストは、どちらもデータを扱う職種ですが、その役割や業務範囲には明確な違いがあります。データエンジニアは、データの収集・処理・保存・管理を担当し、データがスムーズに流れる環境を構築する役割を担います。一方で、データサイエンティストは、データを活用して統計分析や機械学習モデルの開発を行い、ビジネスの意思決定に貢献します。
データエンジニア vs データサイエンティストの役割比較
| 項目 | データエンジニア | データサイエンティスト |
|---|---|---|
| 主な目的 | データの収集・整理・保存を行い、分析しやすい環境を構築 | データを分析し、機械学習モデルや統計分析を活用してビジネス課題を解決 |
| 主な業務 | データパイプラインの構築、データベース設計、ETL処理 | データ分析、機械学習モデルの開発、統計解析 |
| 使用ツール | SQL, Python, Apache Airflow, Hadoop, Spark | Python, R, TensorFlow, Scikit-learn |
機械学習モデルの構築とデータ基盤の関係
データエンジニアは、機械学習に適したデータ基盤を提供し、モデルの学習データを最適化します。
- データのクレンジングと前処理
- 分散処理環境の構築(Hadoop, Spark)
- 機械学習用データのETL処理
- データウェアハウスへのデータ格納(BigQuery, Redshift, Snowflake)
データアナリストとの違い
データエンジニアとデータアナリストは、どちらもデータを扱う職種ですが、目的や業務範囲には明確な違いがあります。データエンジニアは、データの収集・処理・管理を担当し、データが適切に蓄積され、分析可能な状態に整えることが主な役割です。一方、データアナリストは、すでに整備されたデータをもとに、ビジネスに役立つインサイトを抽出し、意思決定をサポートする役割を担います。
分析結果の活用範囲の違い
| 項目 | データエンジニア | データアナリスト |
|---|---|---|
| 主な目的 | データの整理・管理・最適化 | ビジネス課題をデータ分析によって解決 |
| 主な業務 | データパイプライン構築、データベース管理、ETL処理 | データの可視化、KPI分析、レポート作成 |
| 使用ツール | SQL, Python, Airflow, Spark | Excel, Tableau, Power BI, Looker |
BIツールとの関わり
データアナリストは、BIツールを活用してデータを可視化し、経営層やマーケティングチームが理解しやすいレポートを作成します。
- データウェアハウスの設計・管理(BigQuery, Redshift)
- クエリ最適化(SQLチューニング)
- ETLパイプラインの構築
データベースエンジニアとの違い
データエンジニアとデータベースエンジニアは、どちらもデータの管理に関わる職種ですが、その役割には明確な違いがあります。データエンジニアは、データの収集・加工・保存・配信を担当し、データを活用しやすい環境を構築するのが主な業務です。一方、データベースエンジニアは、データベースシステムの設計・運用・最適化を専門とし、データの保管とアクセスの効率化に重点を置きます。
データ基盤の開発 vs データベースの管理
| 項目 | データエンジニア | データベースエンジニア |
|---|---|---|
| 主な目的 | データの流れや処理パイプラインを設計 | データベースのパフォーマンスと保守管理 |
| 主な業務 | データパイプラインの構築、ETL処理、データレイク管理 | データベースの監視、スキーマ設計、バックアップ |
| 使用ツール | Apache Spark, Airflow, Hadoop | MySQL, PostgreSQL, Oracle, MongoDB |
クエリ最適化とインデックス管理の違い
- データエンジニアのアプローチ
- 分散処理(Hadoop, Spark)によるパフォーマンス向上
- データウェアハウスの適切なデータパーティショニング
- ETLパイプラインでのデータ前処理による負荷分散
- データベースエンジニアのアプローチ
- インデックス設計(B+Tree, Hash Index)
- クエリ最適化(SQLチューニング、JOIN戦略の調整)
- キャッシュ機構の活用(Redis, Memcached)
データエンジニアは、データを収集・処理し、分析しやすい環境を整える技術者です。データサイエンティストは機械学習、データアナリストはビジネスインサイト、データベースエンジニアはシステムの安定運用に重点を置く点が大きな違いです。
データエンジニアに求められるスキル
データエンジニアには、データの収集・処理・保存・最適化を効果的に行うための幅広いスキルセットが求められます。プログラミングやデータベース管理に加え、クラウド技術やデータパイプラインの設計・管理能力も不可欠です。本セクションでは、データエンジニアが持つべき主要なスキルについて詳しく解説します。
プログラミングスキル
データエンジニアには、データの収集・処理・保存・管理を効率的に行うためのプログラミングスキルが求められます。特に、データの抽出や変換を自動化するためのスクリプト作成、データパイプラインの構築、分散処理システムの運用には、適切なプログラミング言語の習得が不可欠です。
Python, SQL, Javaの習得
| 言語 | 用途 | 主な使用シーン |
|---|---|---|
| Python | データ処理・ETL・機械学習・API開発 | Pandas, PySpark, ETLスクリプト |
| SQL | データ抽出・変換・管理 | データベース操作、分析クエリ |
| Java | 分散処理フレームワーク・大規模システム開発 | Apache Hadoop, Apache Spark |
スクリプトの自動化(Shell, Airflow)
- Shellスクリプト(Bash, Zsh)を活用したバッチ処理の自動化
- Apache Airflowを使ったデータワークフローの管理とスケジューリング
データベース管理
データエンジニアには、データの収集・処理・保存・管理を効率的に行うためのプログラミングスキルが求められます。特に、データの抽出や変換を自動化するためのスクリプト作成、データパイプラインの構築、分散処理システムの運用には、適切なプログラミング言語の習得が不可欠です。
RDBMS(MySQL, PostgreSQL)
| RDBMS | 特徴 | 主な用途 |
|---|---|---|
| MySQL | 軽量で高性能、オープンソース | Webアプリケーション、データ分析 |
| PostgreSQL | 拡張性が高く、SQLの機能が豊富 | 大規模データ管理、データウェアハウス |
NoSQL(MongoDB, Cassandra, DynamoDB)
| NoSQLデータベース | 特徴 | 主な用途 |
|---|---|---|
| MongoDB | ドキュメント指向DB、JSON形式のデータ保存 | リアルタイムアプリケーション、ログ管理 |
| Cassandra | 分散型、高スループット | ビッグデータ処理、ストリーミングデータの保存 |
| DynamoDB | AWS提供のスケーラブルなNoSQL | サーバーレスアプリケーション、低レイテンシー処理 |
クラウド技術の活用
近年、多くの企業がクラウド環境でのデータ処理を採用しており、データエンジニアにとってクラウド技術の活用は不可欠なスキルとなっています。クラウドプラットフォームを活用することで、スケーラブルなデータ処理、コスト最適化、自動化の効率向上を実現できます。
AWS、GCP、Azureといった主要なクラウドサービスには、それぞれデータエンジニア向けの機能が充実しており、データウェアハウス、ETLツール、ストリーミング処理の最適化に活用されています。
AWS(Redshift, S3, Glue)
- Amazon Redshift: 分析用データウェアハウス
- Amazon S3: オブジェクトストレージ(データレイクの構築)
- AWS Glue: サーバーレスETLツール(データ処理の自動化)
GCP(BigQuery, Dataflow)
- BigQuery: クエリの高速処理が可能なデータウェアハウス
- Dataflow: Apache Beamベースのデータ処理サービス
データパイプラインとETLツール
データパイプラインとETL(Extract, Transform, Load)ツールは、データエンジニアがデータを効率的に処理・管理する上で欠かせない技術です。データパイプラインは、異なるソースからデータを取得し、変換・統合を行いながら、最終的にデータウェアハウスや分析基盤へ送る一連のプロセスを指します。一方、ETLツールは、このプロセスを自動化し、データの整合性を保ちながら効率的に処理を行うためのツールです。
近年、クラウドベースのETLツールやデータパイプラインの自動化ツールが進化し、大量のデータを高速かつ柔軟に処理することが求められています。
Apache Airflow, Talend, dbtの活用
| ツール | 用途 |
|---|---|
| Apache Airflow | ワークフロー管理とスケジューリング |
| Talend | GUIベースのETLツール |
| dbt | データ変換・クレンジング(SQLベース) |
データ変換・統合のベストプラクティス
- データの正規化・非正規化の適切なバランス
- スキーマ変更に強い設計
- パフォーマンスを考慮したパーティショニング
データエンジニアには、プログラミングスキル、データベース管理、クラウド技術、ETLツールの活用能力が求められます。特に、データパイプラインの最適化やデータ変換処理のスキルを高めることで、企業のデータ活用を加速させることができます。
データエンジニアのキャリアパス
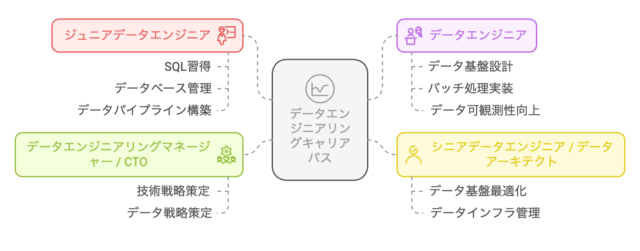
データエンジニアは、初心者から経験を積むことで、より高度なデータ処理やクラウド技術の専門家へと成長できます。本セクションでは、データエンジニアのキャリアパスを「初級・中級・上級」に分け、それぞれに必要なスキルや学習方法について詳しく解説します。
初級(ジュニアデータエンジニア)
ジュニアデータエンジニアは、データエンジニアリングの基礎を学びながら、実務経験を積んでスキルを向上させる段階です。主な業務は、データの収集や前処理、ETLプロセスの一部の実装、データベースの管理補助などが中心となります。
このレベルでは、PythonやSQLの基礎的なプログラミングスキル、データベースの基本操作、ETLツールの使い方を習得することが重要です。また、クラウドサービスの基本を理解し、小規模なデータパイプラインの構築を経験することで、次のキャリアステップへと進む準備ができます。
必要なスキルと学習方法
| カテゴリ | 必要なスキル | 学習方法 |
|---|---|---|
| プログラミング | Python, SQLの基礎 | オンライン講座(Udemy, Coursera) |
| データベース | RDBMS(MySQL, PostgreSQL) | SQLの実践演習(LeetCode, SQLZoo) |
| ETL処理 | データ抽出・変換・ロードの基本 | Apache Airflowの基礎チュートリアル |
| クラウド基盤 | AWS, GCPの基本 | 無料のクラウド学習プログラム(AWS Skill Builder, Google Cloud Skills Boost) |
最初のキャリアの築き方
- Python・SQLの基礎を習得
- 個人プロジェクトを通じて実践経験を積む(Kaggle, Google Colab)
- オープンソースプロジェクトやGitHubにコードを公開
- ジュニアデータエンジニアとしてのインターン・エントリー求人に応募
中級(データエンジニア / ETL開発者)
中級レベルのデータエンジニアは、データの効率的な処理・管理に加え、より高度なデータパイプラインの設計・運用を担当します。データの整合性を確保しながら、スケーラブルで安定したシステムを構築する能力が求められます。特に、ETL(Extract, Transform, Load)処理の自動化や最適化が重要な業務となります。
このレベルでは、SQLやPythonを用いたデータ処理の最適化、クラウド環境でのETLパイプラインの構築、ストリーミングデータ処理の理解が必須です。また、Apache Airflowやdbt、TalendなどのETLツールを活用し、データの統合と変換をより効果的に実施するスキルも必要となります。
より高度なデータ処理の知識
- データパイプラインの設計と管理(Apache Kafka, Apache Spark, dbt)
- データの正規化・非正規化の設計
- ストリーミングデータ処理(Google Dataflow, AWS Kinesis)
クラウド技術とスケールの考え方
- AWS Lambda, Glueを活用したサーバーレスETL処理
- GCP BigQueryを用いた分散クエリ処理
- Kubernetes(k8s)を用いたデータ処理のコンテナ化
上級(データアーキテクト / MLエンジニア)
上級レベルのデータエンジニアは、データの設計・管理にとどまらず、企業全体のデータ戦略を支えるデータアーキテクチャの構築や、機械学習(ML)モデルのためのデータ基盤の最適化を担います。大規模なデータ処理や分散システムの設計、高度なクラウド技術の活用が求められるため、より専門的な知識と実践的な経験が必要になります。
データアーキテクトは、データウェアハウスやデータレイクの設計、データパイプラインの最適化、データガバナンスの導入を担当します。一方、MLエンジニアは、機械学習モデルの学習や推論のためのデータ処理環境を整備し、リアルタイムデータ処理やMLOpsの実装に取り組みます。
大規模データ基盤の設計
- データガバナンスの知識(データライフサイクル管理、GDPR/CCPA対応)
- データレイクとデータウェアハウスの設計(Snowflake, Amazon Redshift Spectrum, Databricks)
- 大規模なETLアーキテクチャの設計(Lambdaアーキテクチャ, Kappaアーキテクチャ)
データガバナンスとセキュリティの確保
- アクセス制御と監査ログの管理
- データマスキングと暗号化の実施
- データクオリティの維持と監視(Great Expectationsなど)
データエンジニアのキャリアは、ジュニア → 中級 → 上級と進むにつれ、データ処理の高度化・クラウド技術の活用・データ戦略の設計へと発展します。キャリアの各ステージで求められるスキルを習得することで、データエンジニアとしての市場価値を高めることができます。
データエンジニアになるには?
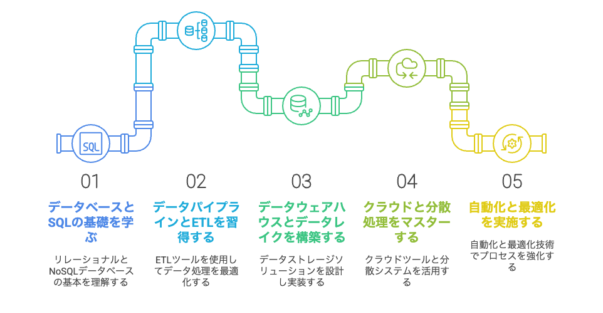
データエンジニアになるためには、データの収集・処理・保存に関する技術を学び、実践的なスキルを習得することが重要です。本セクションでは、データエンジニアを目指すための学習方法や資格、ポートフォリオの作成方法について詳しく解説します。
学習方法とおすすめの教材
データエンジニアとしてのスキルを習得するためには、適切な学習方法を選び、実践的な知識を身につけることが重要です。データの収集・処理・管理に必要なプログラミングスキル、データベースの設計、クラウド環境の活用方法など、多岐にわたるスキルを体系的に学ぶ必要があります。
現在では、無料・有料を問わず、多くのオンライン講座や教材が提供されており、自分のレベルや目標に応じた学習が可能です。また、実践的なプロジェクトを通じてスキルを磨き、ポートフォリオを充実させることが、キャリアアップの大きな助けになります。
無料で学べるオンライン講座
| プラットフォーム | 講座名 | 主な内容 |
|---|---|---|
| Coursera | Google Cloud Data Engineering | データパイプラインの構築、BigQueryの活用 |
| Udacity | Data Engineering Nanodegree | ETL, Apache Airflow, データウェアハウスの構築 |
| Google Cloud Skills Boost | BigQuery Fundamentals | Google Cloud上でのSQL処理とデータ分析 |
| AWS Skill Builder | AWS Certified Data Analytics | AWS Glue, Redshift, S3を使ったデータ処理 |
実践的なプロジェクトの進め方
- Webスクレイピングを活用したデータ収集(Python, BeautifulSoup)
- ETLパイプラインの構築(Apache Airflow, dbt)
- ストリーミングデータ処理(Kafka, Spark Streaming)
- クラウドデータウェアハウスの設計(BigQuery, Snowflake)
資格とキャリア形成
データエンジニアとしてのキャリアを築くうえで、専門的な知識やスキルを証明する資格の取得は大きなメリットとなります。クラウド技術やデータベース管理、ETL処理などの知識を体系的に学ぶことで、実務での応用力が向上し、転職やキャリアアップにも有利に働きます。
また、資格取得だけでなく、実際のプロジェクト経験やポートフォリオの充実も重要です。企業が求めるデータエンジニアのスキルセットを理解し、それに沿った学習と実務経験を積むことで、市場価値の高いエンジニアとして活躍できます。
AWS, GCP, Azureの認定資格
| クラウド | 資格名 | 対象スキル |
|---|---|---|
| AWS | AWS Certified Data Analytics | Redshift, S3, Glue, QuickSight |
| GCP | Google Cloud Professional Data Engineer | BigQuery, Dataflow, Pub/Sub |
| Azure | Azure Data Engineer Associate | Azure Synapse, Data Factory, Cosmos DB |
データエンジニアとしてのポートフォリオ作成
- データパイプラインの設計・構築経験
- ETLツールを活用したデータ処理プロジェクト
- クラウド環境(AWS, GCP, Azure)でのデータ基盤の構築
- BIツールを使ったデータ可視化
- GitHubでのソースコード管理と公開
まとめ
データエンジニアになるためには、プログラミングやデータ処理の学習を進め、クラウド資格を取得し、実践的なプロジェクトを通じてスキルを証明することが重要です。特に、ポートフォリオの充実が採用時に大きな強みとなるため、GitHubやBIツールを活用してアウトプットを積極的に行いましょう。


