
近年、多くの企業がシステムの安定性と運用効率を向上させるために SRE(Site Reliability Engineer:サイト信頼性エンジニア) を導入しています。SREは、ソフトウェアエンジニアリングのアプローチを活用し、システムの可用性・スケーラビリティ・パフォーマンスを向上させる役割を担う職種 です。本記事では、SREの仕事内容、必要なスキル、年収、市場価値、キャリアパス、学習ロードマップ まで詳しく解説します。
SRE(Site Reliability Engineer)とは?
SRE(Site Reliability Engineer)は、システムの可用性やパフォーマンスの向上を目的とし、IT運用の自動化・最適化を進める役割を担います。従来の運用エンジニアとは異なり、SREはソフトウェアエンジニアリングの手法を活用し、インフラの信頼性を向上させる点が特徴です。
SREの特徴と役割
SREは、ソフトウェアエンジニアとインフラエンジニアの両方のスキルを兼ね備え、システム運用の自動化を推進します。
- システムの可用性向上 - ダウンタイムを最小限に抑え、安定した稼働を実現。
- 運用の自動化 - 手動オペレーションを排除し、スクリプトやIaC(Infrastructure as Code)を活用。
- パフォーマンスの最適化 - システムの負荷を監視し、適切なスケーリングを実施。
- 障害対応とインシデント管理 - 迅速な障害復旧と影響範囲の最小化。
SREの目的とは?
SREの主な目的は、企業のITシステムを高可用性・高パフォーマンスで維持しながら、運用の効率化を進めることです。具体的には、以下の3つのポイントに重点を置いています。
- 可用性の向上 - SLA(Service Level Agreement)を満たし、システムの継続的な稼働を確保。
- スケーラビリティの確保 - 負荷に応じたリソースの最適化と自動スケーリング。
- 運用の自動化 - 手作業によるオペレーションを削減し、エラーの発生を防ぐ。
SREと従来の運用エンジニアの違い
従来のインフラエンジニアやシステム運用エンジニアとの大きな違いは、「運用をコード化し、システムの信頼性を向上させる」 というアプローチです。以下の表で比較します。
| 項目 | SRE(Site Reliability Engineer) | 従来の運用エンジニア |
|---|---|---|
| アプローチ | ソフトウェア開発を活用し、システム運用を自動化 | 手動によるオペレーションが中心 |
| 運用の効率化 | Infrastructure as Code(IaC)を活用 | スクリプトの手作業による運用が多い |
| 監視と対応 | モニタリングツール(Prometheus、Datadog)を活用し、障害を予測・自動復旧 | 障害発生後に手動で復旧対応 |
| コードの活用 | Python、Go、Bash などを活用して運用の自動化 | コマンドやスクリプトを手動で実行 |
SREは、「ソフトウェアで運用課題を解決する」 という考え方に基づいており、システムの安定性を維持しながら、エンジニアの負担を減らす役割を担っています。
SRE(Site Reliability Engineer)が誕生した経緯
SRE(Site Reliability Engineer)正直あまり馴染みのないエンジニアの方も老いのではないでしょうか?
SREは比較的新しい職種であり、Googleが2003年に考案 した概念が始まりです。それ以前のIT業界では、開発(Dev)と運用(Ops)が明確に分かれており、さまざまな課題が存在していました。
SREが生まれる前の問題点
現在では多くの企業で導入されているSRE(Site Reliability Engineer)ですが、その誕生の背景には、従来のIT運用における「開発(Dev)」と「運用(Ops)」の対立という深刻な問題がありました。
特に、システムの成長とともに以下のような課題が顕在化していました。
- 開発チーム(Dev) - 新機能を素早くリリースしたいが、運用の負担が増える。
- 運用チーム(Ops) - システムの安定性を優先し、新しい変更をなるべく抑えたい。
- トラブル対応の属人化 - 障害発生時に特定のエンジニアしか対応できない。
- 運用作業の負担増大 - インフラが拡張されるにつれて、手作業での対応が限界に。
このような課題を解決するために、Googleが「ソフトウェアエンジニアリングの手法で運用を最適化する」というコンセプトのもと、SREという新しい職種を生み出しました。
開発(Dev)と運用(Ops)の対立
従来のIT業界では、開発チーム(Dev) が新機能を素早くリリースしようとする一方で、運用チーム(Ops) はシステムの安定性を重視し、頻繁な変更を避ける傾向がありました。その結果、以下の問題が発生していました。
- 開発が機能を作っても、運用チームが「不安定だから」とリリースを拒否
- 運用チームが安定性を優先し、バージョンアップを遅らせる
- 開発と運用のコミュニケーションがうまくいかず、トラブル対応に時間がかかる
この「開発 vs 運用」の対立を解消するために、Googleが考えたのが SRE(Site Reliability Engineering) という概念でした。
SREの誕生(2003年:Google)
Googleは、システムの安定性と開発スピードの両方を向上させるために、「運用をソフトウェアエンジニアリングで解決する」 という考え方を採用しました。
その結果、生まれたのが 「SRE(Site Reliability Engineer)」 という新しい職種です。 SREは、単なるインフラ管理者ではなく、システムの信頼性を向上させるためにコードを書く運用エンジニア です。
SREの導入で変わったこと
GoogleのSRE導入後、以下のような運用改善が実現しました。
- 障害の自動復旧
- インフラの監視やアラート対応を自動化(Prometheus、Datadog)
- 異常検知時に自動復旧する仕組みを開発(Self-Healing System)
- デプロイの高速化
- Infrastructure as Code(IaC)を活用し、インフラの構築をスクリプトで管理(Terraform、Ansible)
- CI/CDの導入により、本番環境へのデプロイを自動化(Jenkins、GitHub Actions)
- SLO(Service Level Objective)の導入
- システムの信頼性を数値化し、適切なエラーバジェットを設定
- エラーバジェットを消費しすぎると新機能リリースを制限
Googleの成功を受けて、Facebook、Netflix、Amazonなどの企業もSREを導入し、今では多くの企業で採用される職種となっています。
なぜSREが必要とされるのか?
現在のITシステムは クラウド環境、マイクロサービス、コンテナ技術 などを活用することで、従来よりも複雑化しています。 そのため、従来の「運用エンジニア」では対応できない課題が増えてきました。
特に 大規模なシステムでは、手作業の運用ではスケールしない ため、SREのような「運用をコード化する」アプローチが必要不可欠になっています。
SREがなかった現場との違い
もしあなたの現場にSREがいなかったとしたら、「従来の運用エンジニア」がその役割を担っていた 可能性が高いです。
しかし、手動運用の限界や、開発スピードの要求が高まる中で、近年では SREのように「運用の自動化」を専門とする職種が必要 になっています。
SREは、これからのインフラ運用のスタンダードになりつつある。
SREの仕事内容
SRE(Site Reliability Engineer)は、システムの安定運用とパフォーマンスの最適化を目的とし、インフラの信頼性を高める業務を担当します。運用の自動化やインシデント対応を通じて、システムの継続的な改善を行います。
システムの安定運用とパフォーマンス管理
システムの可用性と信頼性を維持し、ユーザーに安定したサービスを提供するための業務を担当します。
モニタリングとアラート管理
システムの異常をリアルタイムで検知し、迅速に対応するための監視ツールを活用します。
- Prometheus - オープンソースのモニタリングツールで、リアルタイムのメトリクス収集を実施。
- Grafana - ダッシュボードを用いた可視化ツールで、メトリクスの分析を行う。
- Datadog - クラウド環境の監視ツールとして利用され、アプリケーションやインフラのパフォーマンスを監視。
- アラート管理 - システムの異常検知時にSlackやPagerDutyへ自動通知。
インシデント対応と障害復旧
システム障害が発生した際に、影響を最小限に抑え、迅速な復旧を行うためのプロセスを実施します。
- 障害の特定とログ分析 - システムログ、アプリケーションログの分析を行い、原因を特定。
- 復旧対応の自動化 - Self-Healing(自己修復)機能を導入し、自動的にリカバリー。
- オンコール対応 - インシデント発生時に迅速に対応し、影響を最小限に抑える。
- ポストモーテム(事後分析) - 障害発生後に根本原因を分析し、再発防止策を策定。
運用の自動化と信頼性向上
手作業による運用業務を最小限に抑え、システムの安定性を向上させるために自動化を推進します。
Infrastructure as Code(IaC)の活用
インフラの構築や設定管理を自動化し、環境の一貫性を維持するために以下の技術を活用します。
- Terraform - クラウドリソースの管理をコード化し、一貫したインフラ管理を実現。
- Ansible - サーバー構成の自動化を行い、手作業によるミスを削減。
- CloudFormation - AWSの環境構築をコードベースで管理。
CI/CDパイプラインの構築
継続的インテグレーション(CI)と継続的デリバリー(CD)を実施し、システムの変更を迅速かつ安全に適用できるようにします。
- Jenkins - CI/CDの自動化ツールとして、ビルドやデプロイを管理。
- GitHub Actions - コードの変更を自動的にテストし、本番環境へ適用。
- ArgoCD - Kubernetes環境における継続的デプロイメントを管理。
SREは、これらの技術を駆使してシステムの安定性と効率性を向上させ、最適な運用を実現します。
SREに求められるスキル
SRE(Site Reliability Engineer)として活躍するためには、システム運用や自動化に関する幅広い技術スキルが求められます。特に、クラウド環境の構築・管理、プログラミングスキル、モニタリングツールの活用などが必須となります。本記事では、SREが習得すべきスキルセットを紹介します。
必須スキル
SREにとって不可欠な技術スキルを解説します。これらのスキルを身につけることで、システムの安定運用や効率的なインフラ管理が可能になります。
プログラミング・スクリプト言語
SREは、手作業によるオペレーションを排除し、システム管理や運用の自動化を推進する役割を担います。そのため、以下のプログラミング言語やスクリプトの習得が必須です。
- Python - 自動化スクリプトやAPI連携の実装。
- Go(Golang) - 高速な処理を実現し、モニタリングツールの開発に活用。
- Bash / Shellスクリプト - サーバー管理やインフラ設定の自動化。
クラウドとコンテナ技術
SREはクラウド環境を活用し、スケーラブルなシステムを構築することが求められます。そのため、主要なクラウドプラットフォームやコンテナ技術の理解が必須です。
- AWS - EC2、S3、RDS、Lambda、EKSなどの活用。
- Azure - Azure Virtual Machines、Azure Kubernetes Service(AKS)。
- GCP(Google Cloud Platform) - GKE(Google Kubernetes Engine)、Cloud Functions。
- Docker - コンテナ化技術を活用し、開発・運用の効率を向上。
- Kubernetes - コンテナオーケストレーションツールで、大規模システムの管理を自動化。
モニタリングとパフォーマンス管理
システムの安定運用には、リアルタイムの監視やアラート管理が欠かせません。SREは、以下のモニタリングツールを活用して、システムのパフォーマンスを最適化する必要があります。
- Prometheus - オープンソースのモニタリングツールで、メトリクス収集と可視化を実施。
- Datadog - クラウド環境の監視とログ管理を統合。
- New Relic - アプリケーションのパフォーマンス監視をリアルタイムで実施。
SREは、これらのスキルを習得することで、システムの安定性を向上させ、効率的な運用を実現できます。
SREの年収と市場価値
SRE(Site Reliability Engineer)は、システムの安定性を確保し、運用の自動化を推進する専門職です。その需要の高さから、エンジニア職種の中でも比較的高い年収を得ることができます。本記事では、SREの平均年収や市場価値について詳しく解説します。
SREの平均年収
経験やスキルセット、企業の規模によってSREの年収は大きく異なります。特にクラウドやコンテナ技術、IaC(Infrastructure as Code)を活用できるSREは、高年収を得る傾向があります。以下の表は、日本国内および海外のSREの平均年収をまとめたものです。
| 経験年数 | 日本国内(年収) | 海外(年収) |
|---|---|---|
| 未経験~3年 | 500万~800万円 | 80,000~110,000ドル |
| 3~5年 | 800万~1,200万円 | 110,000~150,000ドル |
| 5年以上 | 1,200万~2,000万円 | 150,000~200,000ドル |
未経験からのスタートでも、3年程度の経験を積めば年収800万円以上を目指すことが可能です。また、海外の企業ではさらに高い報酬を得られるケースが多く、特に米国では年収150,000ドル(約2,000万円)以上の求人も少なくありません。
SREの市場価値
近年、SREの市場価値は急速に高まっています。これは、クラウド環境の普及やDevOpsの推進により、システムの安定運用と自動化を実現するエンジニアが求められているためです。特に以下のような技術スキルを持つSREは、企業から高い評価を受けます。
クラウドとコンテナ技術の需要増加
多くの企業がオンプレミス環境からクラウドへ移行しており、AWS、Azure、GCP のスキルを持つSREの需要が急増しています。
- AWS(Amazon Web Services) - EC2、RDS、EKS などの運用スキル。
- Azure - Azure Kubernetes Service(AKS)、仮想マシン管理。
- GCP(Google Cloud Platform) - Google Kubernetes Engine(GKE)、Cloud Functions。
- Docker - コンテナ化技術を活用し、開発・運用の効率を向上。
- Kubernetes - 大規模システムのコンテナオーケストレーション。
インフラの自動化とDevOpsの加速
システムの運用効率を向上させるために、IaC(Infrastructure as Code)やCI/CDを活用できるSREの市場価値が高まっています。
- Terraform - クラウドリソースの管理をコード化し、一貫したインフラ管理を実現。
- Ansible - サーバー構成の自動化を行い、手作業によるミスを削減。
- CI/CDの構築 - Jenkins、GitHub Actions、ArgoCD を活用した継続的デリバリー。
高収入を狙うためのスキルセット
市場価値の高いSREになるためには、以下のスキルの習得が重要です。
- 関連資格の取得 - AWS Certified DevOps Engineer、Google Professional Cloud DevOps Engineer。
- セキュリティ対策 - クラウド環境でのアクセス管理やデータ暗号化の知識。
- Infrastructure as Code(IaC) - Terraform、CloudFormation の活用。
- ネットワーク管理 - VPC、VPN、ロードバランサーの運用。
これらのスキルを習得し、実務経験を積むことで、SREとしての市場価値を高め、高収入を狙うことが可能になります。
SREのキャリアパス
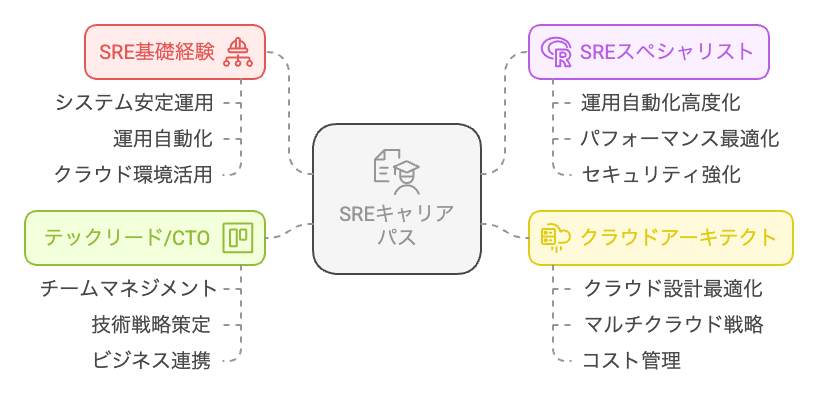
SRE(Site Reliability Engineer)は、システムの信頼性を向上させる役割を担い、運用の自動化を推進する重要な職種です。経験を積むことで、より高度な技術職や管理職へとキャリアアップすることが可能です。本記事では、SREとしてのキャリアの選択肢を紹介します。
SREからのキャリアパス
経験を積んだ後、SREはさまざまなキャリアの選択肢を持つことができます。以下は、SREの主要なキャリアパスの例です。
SREスペシャリスト
運用の自動化と信頼性向上の専門家として、より高度な技術スキルを習得し、システムのパフォーマンス最適化や障害対応の自動化に特化します。
- 運用自動化の深化 - Infrastructure as Code(IaC)、CI/CDの最適化。
- システムのパフォーマンス最適化 - SLO(Service Level Objective)の管理と可用性向上。
- インシデント管理の高度化 - AIを活用した障害検知・復旧の自動化。
クラウドアーキテクト
AWS、GCP、Azureなどのクラウド環境におけるアーキテクチャ設計や最適化を担当し、企業のクラウドインフラを構築・運用します。
- クラウド設計 - マルチクラウド・ハイブリッドクラウド環境の設計。
- クラウド移行 - オンプレミスからクラウドへのシステム移行プロジェクトの推進。
- コスト最適化 - クラウドコスト管理とパフォーマンスのバランスを最適化。
テックリード / CTO
開発・運用チームを率い、技術戦略を策定し、企業の成長を支えるリーダー的なポジションを目指します。
- チームマネジメント - SREチームの組織構築と運営。
- 技術戦略の策定 - 企業のITインフラの長期戦略を立案。
- 経営層との連携 - ビジネス目標と技術戦略の整合性を確保。
SREのスキルを活かしながら、より専門的な分野に進むか、管理職としてキャリアを築くかは、個人の志向によって決まります。将来のキャリアプランを明確にし、自分に合った道を選びましょう。
SREになるための学習ロードマップ
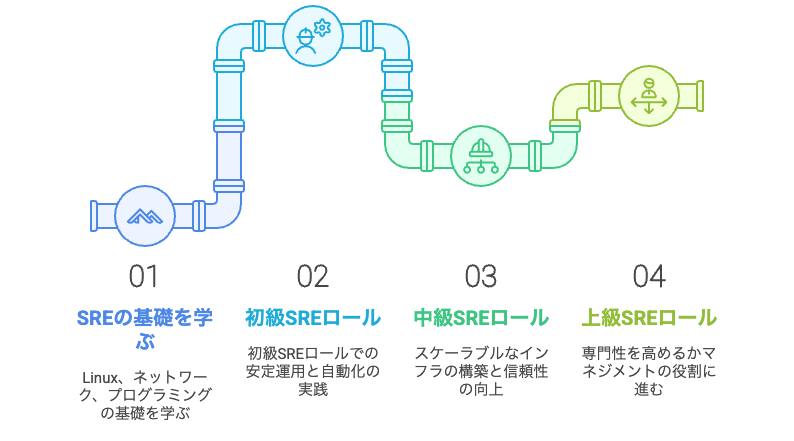
SRE(Site Reliability Engineer)は、システムの可用性と信頼性を維持しながら、運用の自動化を推進する重要な職種です。未経験者がSREを目指すために必要な学習ステップを紹介します。
学習ステップ
基礎から実務レベルのスキルを身につけるための学習方法を段階的に解説します。
インフラとクラウドの基礎学習
SREは、クラウド環境を活用し、インフラの管理を行うため、以下の技術の習得が必須です。
- Linuxの基本 - コマンドライン操作、シェルスクリプト、ユーザー管理、権限設定。
- クラウド基礎 - AWS、GCP、Azure の主要サービス(EC2、S3、IAM、VPC)。
- ネットワーク管理 - TCP/IP、DNS、ロードバランシング、ファイアウォール設定。
運用の自動化とIaCの習得
手作業によるインフラ管理を減らし、自動化を実現するために、Infrastructure as Code(IaC)を習得します。
- Terraform - クラウドインフラをコードで管理し、一貫した環境を構築。
- Ansible - サーバー構成管理の自動化により、手動設定のミスを防ぐ。
- CloudFormation - AWSの環境構築をコードベースで管理。
モニタリングとパフォーマンス管理
システムの異常をリアルタイムで検知し、迅速に対応するための監視ツールの習得が必要です。
- Prometheus - メトリクスを収集し、システムの可視化を実現。
- Grafana - データをダッシュボードで表示し、異常を分析。
- Datadog - クラウド環境のログ監視とパフォーマンス管理。
これらのスキルを習得し、実務経験を積むことで、SREとしてのキャリアをスタートできます。


